前の10件 | -
Chromebook でどれだけ仕事はブーストできるのか? [ハードウェア]
C302CA(Chromebook)を仕事のメイン機として使い始めて1カ月程度たちました。
Chromebookは「ブログ執筆とか動画閲覧とかのライトな用途に〜」という記事が多いですが、1カ月使い込んでみて自分としては「仕事のスピードを加速してくれるもの」であると確信しています。仕事の環境を徹底的にオンラインサービスに移行することで自分(環境)を身軽にし、やりたいこと・やらなくてはいけないことに集中する、そんなジブン変革のツールとしてChromebookをオススメしていきたいと思います。

「仕事のスピードを加速してくれるもの」と確信に至った経緯
ある日のこと。
朝会社でWindows PCを立ち上げる。最近どうも動きがノロいな。プロセスを見てみるとウィルス対策ソフトがCPUを30%ぐらい食っている。しょうがないのでスマホで仕事をしながら負荷のかからない仕事をするか。あ、Pythonスクリプトの検証しないと。そういえばローカルにも環境作ったほうが良いからAnaconda入れるか。あー遅い、実行するまで30分コースだ、、。 2年間クリーンインストールしていないPCなので再インストールすればシャキっとする可能性はあるものの、ファイルの入れ替えでまた時間を食うのは嫌だな。
こんなモヤモヤをこの数カ月抱えていました。
私40代の人間ですが、社会に出てから15年間Windowsべったりの仕事スタイルでした。技術職→コンサル→データ屋(?)と職種は変わりつつも基本的にはWindows。当たり前のように受け入れている仕事のツールが時代に則していないかもと思い始めていたこの頃、たまに Chromebookを触っていました。 もともとAndroidアプリのテスト用に購入していたASUS C100PAという機種で、たまに触るもののあくまで実験用。致命的に遅くはないものの、機能などの問題から仕事では使えないよなぁという漠然とした感触でした。
Chromebookはジワジワ できることが拡がってきていていますが、 「ここまで使える」みたいな感じで「使いづらいものを無理矢理使えるように思い込もうとしている」みたいな言われ方をされるのが多く、自分もそう思っていました。 一方で Chromebookで作業している時「なんか楽」という不思議な感覚がありました。それの原因はまだその時は分かりませんでした。
そんな中、ある日ChromebookでLinuxアプリケーションが動かせるようになる、Crostiniプロジェクトの記事を見ました。
※ちなみにCrostiniはまだ一部の機種のdevチャネルでしか動かず、動作も不安定です
日頃からWindowsでローカル環境を作るのに毎回イライラしている自分としてはこれは嬉しい知らせです。クラウドメインで使いながらローカルアプリの検証もできます。そういえばChromebookはエントリー機種しか触ったことないけど、ネットで評判の良いChromebookの上位機種を買っといてCrostiniの準備をしておくか〜、と思い ASUS C302CA を欲しいものリストに入れておきました。 Core m3-6Y30 プロセッサ 搭載で、Chromebookを動作させるには十分パワフルな機体です。
仕事でモヤモヤしていた時、気分転換で自分用としてC302CAをポチってみました。届いてちょろっと触ってみると、、、それは「衝撃」。今まで仕事で使っていた重いWebツールがサクサク動き、思考を止めることがありません。快感としか言えないような使用感で、すぐにメインマシンとなりました。
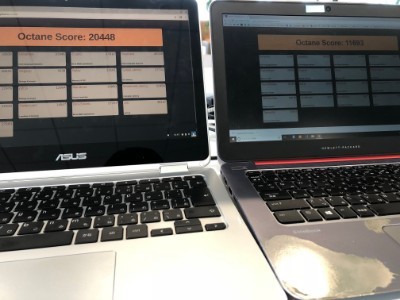
ちなみにどのぐらい違うかを比較するためにほぼ近いパワーのCPUを持つWindowsマシンと比較してみたのが以下になります。右のWindows HP Folio 1020 は12万円@2年前のモデル(5Y51)、左のChromebook C302CA は7万円@1年前のモデル(6Y30)です。
その1 Octaneベンチマークを比較してみよう(ほぼダブルスコア)
その2 chromeを立ち上げる(Windows側の起動と同時に動画開始、その後Chromebookを起動)
その3 gmail起動これだけ違う
・Chromebook
・Windows
その4 slack起動これだけ違う
・Chromebook
・Windows
そしてもう一つ、使っているうちに分かってきたのは『 Chromebookで仕事している時「なんか楽」という不思議な感覚 』の原因、それはローカルファイル、ローカルにインストールされたソフトウェアに極力依存しないこと、であることに気づきました。実は「仕事するか〜」から実際に内容を編集できる工程に入るまでに、結構な時間を「ファイルの操作」に使っています。それはファイルを探し、開き、やり取りする、という時間。ローカルの重たいソフトウェアを立ち上げる時間。これ結構馬鹿にできない労力がかかっていて、普通のオフィスワーカーで実感値で1割はあると思います。Chromebookは「ローカルファイル」や一部「ローカルソフト※」も扱えますがそこを使いやすくしようというUI設計でもないので、極力ローカルファイルを使わない仕事の仕方に自然と変わり、ストレスが減らせることが分かりました。
※AndoroidアプリやChromeApp(一種のPWA)
使うツールを変え、使い方も変えてみる
こんなことから思い切ってメイン環境をChromebookに乗り換えてみました。Chromebookでできない、PCでしかできない作業というものが、今働き方改革を求められている中で「生産性を下げる原因」とリンクしてきているのではないかと思い始めています。
図式化してみます。
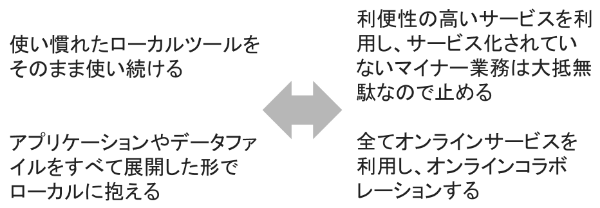
これBPR的な視点で置き換えるとこんな感じになります。
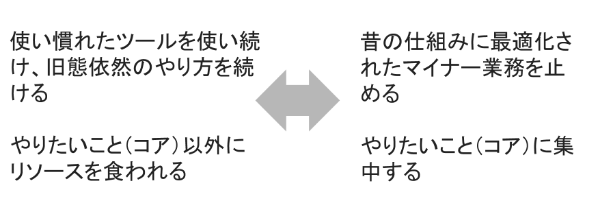
元BPRコンサルの視点で言うと、こういうところってプロジェクトの最初に手をつける項目ですね。「やってはいけないこと」が自然と「できないこと」になっている Chromebookを使うことによって、古い習慣を断ち切り好循環を生み出すキッカケができます。
さて、こちらは触りの記事になりますので、最後にChromebook導入とセットで捨てるべき習慣を以下に3つ書き出してみました。これらの古い習慣を捨てることで生産性のブーストが可能になります
◯Chromebook導入と同時に捨てるべき3つの習慣
(1)MS Office
これを書いた瞬間に9割の人が離脱しそうですが(笑)、Officeから離れることは全然可能です。自分は前からこの施策は進めていて、自分発信のOfficeファイルは全てgoogleのツールを使用してます。唯一「動作が遅い」弱点があったんですが、速いChromebookを使うことで解決しています。
皆さん以下のような経験はありませんか?資料を作っているつもりが装飾ばかりいじっている、PC開けない状況でOfficeのファイルが送られてきてVPN繋いでPC開く、メールに添付されてどれが最新か分からないExcel、100ページ近いPower Point、、。これら全て、捨てる気があれば捨てられます。
ちなみにMS Officeが悪いソフトであると言いたいわけではなく、もう少しオンライン作業やコラボレーションが「素の機能で」もっとできてくれると、もっともっと使い勝手が良くなるかなとは思っています。MSさんよろしくお願いします!
(2)デスクトップにモノを置く
PCはファイル、アプリショートカット区別なくデスクトップにアイコンを置けます。でもこれ結構整頓がおろそかになるのと、同じことやるのに複数の手段があり迷いを産む(=認知上ストレスになる)ので悪習です(キッパリ)。ファイルはファイルマネージャ、アプリはドロアーから起動という動作に慣れるととても楽です。
(3)どこにあるか分からないファイル
このファイルどこに最新版があるのかな?ローカルか、誰かのメールか、ファイルサーバーか、、。サービスを使っていれば常に最新版は1つ、サービスによってはロールバックも容易です。ファイル名でバージョン管理なんてことは必要ありません。
どれだけブーストできたかをざっくり数字にしてみよう
計測するのは大変なので推定してみました。
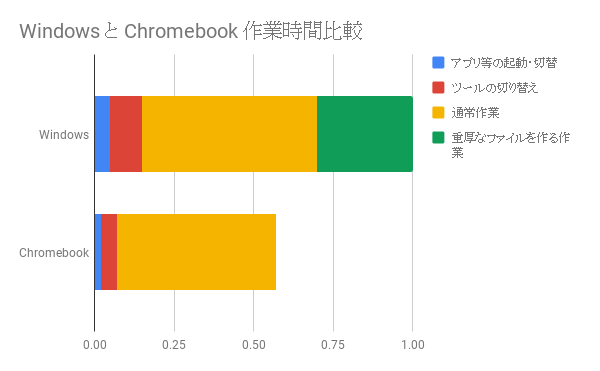
実質ハードによる変更の効果は10~15%程度、それにさらに「よくわからないけど重厚なファイルをいじっている作業」を減らすと大きく生産性を上げられるでしょう。私の場合はOfficeを使わなくなったことが大きいです。皆さん何かしら今までやり続けていた業務というのがあると思います。これを機にバサっと捨ててみてはいかがでしょうか?
最後に
この記事ではChromebookでなぜ生産性がブーストできるのか?の概念を記載しました。
あと2回ぐらいで、より実践的な内容や、現状どうしても代替できない部分を書いていきたいと思います。仕事と気負わなくてもChromebookはプライベートでもとても使いやすい端末なので皆さんぜひ触って試してみてください!
◯2回目予定 実践編
・どうしてもWindowsが必要な場合
・テキストエディタ
・SSH
・開発環境を整える
・R言語を使いたい
・国内系の動画サービス
・目が疲れる
◯3 回目予定 どうしても置き換えられないもの
・特殊なハードウェア
・重めのExcel分析
Chromebookは「ブログ執筆とか動画閲覧とかのライトな用途に〜」という記事が多いですが、1カ月使い込んでみて自分としては「仕事のスピードを加速してくれるもの」であると確信しています。仕事の環境を徹底的にオンラインサービスに移行することで自分(環境)を身軽にし、やりたいこと・やらなくてはいけないことに集中する、そんなジブン変革のツールとしてChromebookをオススメしていきたいと思います。
「仕事のスピードを加速してくれるもの」と確信に至った経緯
ある日のこと。
朝会社でWindows PCを立ち上げる。最近どうも動きがノロいな。プロセスを見てみるとウィルス対策ソフトがCPUを30%ぐらい食っている。しょうがないのでスマホで仕事をしながら負荷のかからない仕事をするか。あ、Pythonスクリプトの検証しないと。そういえばローカルにも環境作ったほうが良いからAnaconda入れるか。あー遅い、実行するまで30分コースだ、、。 2年間クリーンインストールしていないPCなので再インストールすればシャキっとする可能性はあるものの、ファイルの入れ替えでまた時間を食うのは嫌だな。
こんなモヤモヤをこの数カ月抱えていました。
私40代の人間ですが、社会に出てから15年間Windowsべったりの仕事スタイルでした。技術職→コンサル→データ屋(?)と職種は変わりつつも基本的にはWindows。当たり前のように受け入れている仕事のツールが時代に則していないかもと思い始めていたこの頃、たまに Chromebookを触っていました。 もともとAndroidアプリのテスト用に購入していたASUS C100PAという機種で、たまに触るもののあくまで実験用。致命的に遅くはないものの、機能などの問題から仕事では使えないよなぁという漠然とした感触でした。
Chromebookはジワジワ できることが拡がってきていていますが、 「ここまで使える」みたいな感じで「使いづらいものを無理矢理使えるように思い込もうとしている」みたいな言われ方をされるのが多く、自分もそう思っていました。 一方で Chromebookで作業している時「なんか楽」という不思議な感覚がありました。それの原因はまだその時は分かりませんでした。
そんな中、ある日ChromebookでLinuxアプリケーションが動かせるようになる、Crostiniプロジェクトの記事を見ました。
※ちなみにCrostiniはまだ一部の機種のdevチャネルでしか動かず、動作も不安定です
日頃からWindowsでローカル環境を作るのに毎回イライラしている自分としてはこれは嬉しい知らせです。クラウドメインで使いながらローカルアプリの検証もできます。そういえばChromebookはエントリー機種しか触ったことないけど、ネットで評判の良いChromebookの上位機種を買っといてCrostiniの準備をしておくか〜、と思い ASUS C302CA を欲しいものリストに入れておきました。 Core m3-6Y30 プロセッサ 搭載で、Chromebookを動作させるには十分パワフルな機体です。
仕事でモヤモヤしていた時、気分転換で自分用としてC302CAをポチってみました。届いてちょろっと触ってみると、、、それは「衝撃」。今まで仕事で使っていた重いWebツールがサクサク動き、思考を止めることがありません。快感としか言えないような使用感で、すぐにメインマシンとなりました。
ちなみにどのぐらい違うかを比較するためにほぼ近いパワーのCPUを持つWindowsマシンと比較してみたのが以下になります。右のWindows HP Folio 1020 は12万円@2年前のモデル(5Y51)、左のChromebook C302CA は7万円@1年前のモデル(6Y30)です。
その1 Octaneベンチマークを比較してみよう(ほぼダブルスコア)
その2 chromeを立ち上げる(Windows側の起動と同時に動画開始、その後Chromebookを起動)
その3 gmail起動これだけ違う
・Chromebook
・Windows
その4 slack起動これだけ違う
・Chromebook
・Windows
そしてもう一つ、使っているうちに分かってきたのは『 Chromebookで仕事している時「なんか楽」という不思議な感覚 』の原因、それはローカルファイル、ローカルにインストールされたソフトウェアに極力依存しないこと、であることに気づきました。実は「仕事するか〜」から実際に内容を編集できる工程に入るまでに、結構な時間を「ファイルの操作」に使っています。それはファイルを探し、開き、やり取りする、という時間。ローカルの重たいソフトウェアを立ち上げる時間。これ結構馬鹿にできない労力がかかっていて、普通のオフィスワーカーで実感値で1割はあると思います。Chromebookは「ローカルファイル」や一部「ローカルソフト※」も扱えますがそこを使いやすくしようというUI設計でもないので、極力ローカルファイルを使わない仕事の仕方に自然と変わり、ストレスが減らせることが分かりました。
※AndoroidアプリやChromeApp(一種のPWA)
使うツールを変え、使い方も変えてみる
こんなことから思い切ってメイン環境をChromebookに乗り換えてみました。Chromebookでできない、PCでしかできない作業というものが、今働き方改革を求められている中で「生産性を下げる原因」とリンクしてきているのではないかと思い始めています。
図式化してみます。
これBPR的な視点で置き換えるとこんな感じになります。
元BPRコンサルの視点で言うと、こういうところってプロジェクトの最初に手をつける項目ですね。「やってはいけないこと」が自然と「できないこと」になっている Chromebookを使うことによって、古い習慣を断ち切り好循環を生み出すキッカケができます。
さて、こちらは触りの記事になりますので、最後にChromebook導入とセットで捨てるべき習慣を以下に3つ書き出してみました。これらの古い習慣を捨てることで生産性のブーストが可能になります
◯Chromebook導入と同時に捨てるべき3つの習慣
(1)MS Office
これを書いた瞬間に9割の人が離脱しそうですが(笑)、Officeから離れることは全然可能です。自分は前からこの施策は進めていて、自分発信のOfficeファイルは全てgoogleのツールを使用してます。唯一「動作が遅い」弱点があったんですが、速いChromebookを使うことで解決しています。
皆さん以下のような経験はありませんか?資料を作っているつもりが装飾ばかりいじっている、PC開けない状況でOfficeのファイルが送られてきてVPN繋いでPC開く、メールに添付されてどれが最新か分からないExcel、100ページ近いPower Point、、。これら全て、捨てる気があれば捨てられます。
ちなみにMS Officeが悪いソフトであると言いたいわけではなく、もう少しオンライン作業やコラボレーションが「素の機能で」もっとできてくれると、もっともっと使い勝手が良くなるかなとは思っています。MSさんよろしくお願いします!
(2)デスクトップにモノを置く
PCはファイル、アプリショートカット区別なくデスクトップにアイコンを置けます。でもこれ結構整頓がおろそかになるのと、同じことやるのに複数の手段があり迷いを産む(=認知上ストレスになる)ので悪習です(キッパリ)。ファイルはファイルマネージャ、アプリはドロアーから起動という動作に慣れるととても楽です。
(3)どこにあるか分からないファイル
このファイルどこに最新版があるのかな?ローカルか、誰かのメールか、ファイルサーバーか、、。サービスを使っていれば常に最新版は1つ、サービスによってはロールバックも容易です。ファイル名でバージョン管理なんてことは必要ありません。
どれだけブーストできたかをざっくり数字にしてみよう
計測するのは大変なので推定してみました。
実質ハードによる変更の効果は10~15%程度、それにさらに「よくわからないけど重厚なファイルをいじっている作業」を減らすと大きく生産性を上げられるでしょう。私の場合はOfficeを使わなくなったことが大きいです。皆さん何かしら今までやり続けていた業務というのがあると思います。これを機にバサっと捨ててみてはいかがでしょうか?
最後に
この記事ではChromebookでなぜ生産性がブーストできるのか?の概念を記載しました。
あと2回ぐらいで、より実践的な内容や、現状どうしても代替できない部分を書いていきたいと思います。仕事と気負わなくてもChromebookはプライベートでもとても使いやすい端末なので皆さんぜひ触って試してみてください!
◯2回目予定 実践編
・どうしてもWindowsが必要な場合
・テキストエディタ
・SSH
・開発環境を整える
・R言語を使いたい
・国内系の動画サービス
・目が疲れる
◯3 回目予定 どうしても置き換えられないもの
・特殊なハードウェア
・重めのExcel分析
わたしが東芝を辞めた、たった一つの理由 [キャリアプラン]
わたし実は東芝出身です。新卒で半導体部門に入社し、データ分析やその仕組みについて考えられる機会をいただいたり、デバイス関連の最高峰の学会に通して発表する機会をいただいたりと、非常にいろいろ育てていただいて、半導体エンジニアとしてのキャリアも順調ななか、丸5年で退職しました。9年前のことです。
何で辞めたんですか?と最近聞かれるので、「いや、予言能力あるんですよw」とはぐらかしたりもするんですが、本当の理由はちょっと重くて、一言で言うと「事業に個性がなくサービス志向が無い文化が辛かった」です。
一つ例を挙げます。当時まだデバイスメーカーは10強ぐらい会社があって、intelが頭一つ抜けている状態。そんな中で「とりあえず追随する」という方針を頑なに取っていました。なので基本的やることはベンチマークと他社がやっている技術のコピー。
事業に個性が無いので、求められる仕事にも個性は不要です。大人数で議論、意見が合わない時は間を取って良い議論ができたと満足する。他社ではこうやっているとか一般論に流される。そんな進め方をしているうちにintelとの差は開くばかり。自分達が一生懸命今立ち上げようとしている技術が、いま仕事で使っているノートPCのintel chipには既に乗っている。こんなペースで自分が事業を引っ張るぐらいの年齢までこの組織あるだろうか?辞めよう、、。1年ぐらい悩み、転職活動の末キャリアチェンジ先が見つかり、辞職しました。
思い返すと「問題先送り文化」とか「労働組合」とかも嫌だったのですが、一番の辞めた理由は上記です。
時代は「マスを煽って買わせる」ことからどんどん「実のあるパーソナライズサービス」に向かっています。耳触りだけのソリューション(水素水とか?)は一瞬受け入れられてもすぐにボロが出て叩かれ無くなります。誰かにはちゃんと役立つモノを作りあげる、そんなことを大事に時間を使っていこうと、東芝消滅のニュースを見ながら気持ちを引き締め直しました。
何で辞めたんですか?と最近聞かれるので、「いや、予言能力あるんですよw」とはぐらかしたりもするんですが、本当の理由はちょっと重くて、一言で言うと「事業に個性がなくサービス志向が無い文化が辛かった」です。
一つ例を挙げます。当時まだデバイスメーカーは10強ぐらい会社があって、intelが頭一つ抜けている状態。そんな中で「とりあえず追随する」という方針を頑なに取っていました。なので基本的やることはベンチマークと他社がやっている技術のコピー。
事業に個性が無いので、求められる仕事にも個性は不要です。大人数で議論、意見が合わない時は間を取って良い議論ができたと満足する。他社ではこうやっているとか一般論に流される。そんな進め方をしているうちにintelとの差は開くばかり。自分達が一生懸命今立ち上げようとしている技術が、いま仕事で使っているノートPCのintel chipには既に乗っている。こんなペースで自分が事業を引っ張るぐらいの年齢までこの組織あるだろうか?辞めよう、、。1年ぐらい悩み、転職活動の末キャリアチェンジ先が見つかり、辞職しました。
思い返すと「問題先送り文化」とか「労働組合」とかも嫌だったのですが、一番の辞めた理由は上記です。
時代は「マスを煽って買わせる」ことからどんどん「実のあるパーソナライズサービス」に向かっています。耳触りだけのソリューション(水素水とか?)は一瞬受け入れられてもすぐにボロが出て叩かれ無くなります。誰かにはちゃんと役立つモノを作りあげる、そんなことを大事に時間を使っていこうと、東芝消滅のニュースを見ながら気持ちを引き締め直しました。
タグ:東芝
【ガジェットレビュー】37degree スマートブレスレット [ハードウェア]
37degreeという中国ブランドのスマートブレスレットを先週から試しています。

http://m.37c.cc/en/index.html
ライフログ好きの人には悪くないかも。
他にない特徴は「血圧、呼吸数、疲れ、心の状態が分かる(自称)」こと。設定すると一般的な活動量指数(歩数、心拍数、睡眠の長さ)+上記の指標を毎時00分ごとにいろいろなシーンで測定してくれます。絶対値としては?ですが、相対値として血圧の連続値は生活習慣見直すにはいいかも(昼寝すると血圧下がる、ラーメン食べると血圧上がる、、)。疲れと心の状態は合っているかどうか分からないので思考が軽い人で試してみます。
ハード的にはバンドに本体をセットするコスト重視型。Fitbit altaとかは格好良いですがバンド全てをデバイス品質で作りこまなくてはいけないのでやはり高くなってしまっていますね。
この機能でAmazon価格で5000円。google playを見る限り数万台は売れてそう。早くこのレベルで戦わないとなぁ。
")
http://m.37c.cc/en/index.html
ライフログ好きの人には悪くないかも。
他にない特徴は「血圧、呼吸数、疲れ、心の状態が分かる(自称)」こと。設定すると一般的な活動量指数(歩数、心拍数、睡眠の長さ)+上記の指標を毎時00分ごとにいろいろなシーンで測定してくれます。絶対値としては?ですが、相対値として血圧の連続値は生活習慣見直すにはいいかも(昼寝すると血圧下がる、ラーメン食べると血圧上がる、、)。疲れと心の状態は合っているかどうか分からないので思考が軽い人で試してみます。
ハード的にはバンドに本体をセットするコスト重視型。Fitbit altaとかは格好良いですがバンド全てをデバイス品質で作りこまなくてはいけないのでやはり高くなってしまっていますね。
この機能でAmazon価格で5000円。google playを見る限り数万台は売れてそう。早くこのレベルで戦わないとなぁ。
37 Degree スマートブレスレット 心拍数計 歩数計 呼吸数計測 血圧測定 疲労監視 歩数計 睡眠モニター Android&IOS対応 (グレー)
- 出版社/メーカー: 37 Degree
- メディア: エレクトロニクス
クラウドストレージ2016
以前の記事 http://komlog2.blog.so-net.ne.jp/2014-01-13から世間の状況も変わってきたのでアップデートしてみました。
○サービスどれにするか
ここら辺の比較はいろんなサイトで行っていると思うので細かいサービス比較は置いといて、雑感的なものを書いておきます。ちなみに今回Yahoobox(プレミア会員50GB) から OneDrive(100GBコース)にしました。決め手は以下です
・OneDriveアプリが優秀になってきた(動画もそこそこ再生してくれます)一方でYahoo boxは危なっかしいまんまでした
・コスト(400->190円へ低減)
と言っている間にOneDriveの価格体系が変わったみたいなので、この分野は定期的に見直しをするのがよさそうですね。
○写真、動画の管理方法のアップグレード
よくクラウドストレージのデフォルトのフォルダ切りでは
Photo
Video
みたいになっていると思うのですが、これ1つで良いなという気がしたので統合することにしました。iPhoneのカメラロールとかそうなっていると思うのですが、振り返る時に画像か動画かというのはあまり関係ないんですよね。
○バックアップ方法のアップグレード
スマホで撮影したデータはオンプレのNAS(Synology DS215j)→クラウドに手動バックアップ、という手順でした。これが微妙に面倒くさかったのですが、OneDriveの場合cloud syncというアプリをSynology にインストールすることで自動同期が取れるようになるので設定してみました。
・移行のコツなど
(1)cloud syncはフォルダを選択しても相手側のクラウドサービスのトップディレクトリからの階層構造をそのまま引き継ぐため、相手側の階層が深いとそのままSynology側のフォルダが深くなってしまいます。今回の場合は写真のサブフォルダをOneDriveトップに持ってくることで上記の問題に対応しました。
(2)(1)の感じでフォルダの準備をしたあと、お互いフォルダ・ファイルが存在する状態で同期をかけてみたのですが、ファイル重複のロジックがファイルの中身を確認するわけではなく同じ名前のファイル・フォルダがあったらリネームして退避するロジックらしく、でっかい退避フォルダが作られてしまいました、、、。なので初回更新時はどちらかを空にした上で同期実行をかけると良いでしょう。Synology側は変換処理がかかるのでクラウド側に飛ばすのがお勧めです。
・注意など
相互同期にした場合、仮に事故って片方消すと両方消えてしまいますがOneDriveはゴミ箱で30日保存されるので、事故ったのに気づいていればリカバリ可能です
ということで管理方法のアップグレード完了。次は100GB越えそうになった時に検討します〜。
○サービスどれにするか
ここら辺の比較はいろんなサイトで行っていると思うので細かいサービス比較は置いといて、雑感的なものを書いておきます。ちなみに今回Yahoobox(プレミア会員50GB) から OneDrive(100GBコース)にしました。決め手は以下です
・OneDriveアプリが優秀になってきた(動画もそこそこ再生してくれます)一方でYahoo boxは危なっかしいまんまでした
・コスト(400->190円へ低減)
と言っている間にOneDriveの価格体系が変わったみたいなので、この分野は定期的に見直しをするのがよさそうですね。
○写真、動画の管理方法のアップグレード
よくクラウドストレージのデフォルトのフォルダ切りでは
Photo
Video
みたいになっていると思うのですが、これ1つで良いなという気がしたので統合することにしました。iPhoneのカメラロールとかそうなっていると思うのですが、振り返る時に画像か動画かというのはあまり関係ないんですよね。
○バックアップ方法のアップグレード
スマホで撮影したデータはオンプレのNAS(Synology DS215j)→クラウドに手動バックアップ、という手順でした。これが微妙に面倒くさかったのですが、OneDriveの場合cloud syncというアプリをSynology にインストールすることで自動同期が取れるようになるので設定してみました。
・移行のコツなど
(1)cloud syncはフォルダを選択しても相手側のクラウドサービスのトップディレクトリからの階層構造をそのまま引き継ぐため、相手側の階層が深いとそのままSynology側のフォルダが深くなってしまいます。今回の場合は写真のサブフォルダをOneDriveトップに持ってくることで上記の問題に対応しました。
(2)(1)の感じでフォルダの準備をしたあと、お互いフォルダ・ファイルが存在する状態で同期をかけてみたのですが、ファイル重複のロジックがファイルの中身を確認するわけではなく同じ名前のファイル・フォルダがあったらリネームして退避するロジックらしく、でっかい退避フォルダが作られてしまいました、、、。なので初回更新時はどちらかを空にした上で同期実行をかけると良いでしょう。Synology側は変換処理がかかるのでクラウド側に飛ばすのがお勧めです。
・注意など
相互同期にした場合、仮に事故って片方消すと両方消えてしまいますがOneDriveはゴミ箱で30日保存されるので、事故ったのに気づいていればリカバリ可能です
ということで管理方法のアップグレード完了。次は100GB越えそうになった時に検討します〜。
自宅のビデオ再生環境をアップデートしよう [ハードウェア]
デジカメをPowershot G7Xに買い換えて、フルHDの60P動画が撮れるようになったのはいいのですが、今の家の環境だとストリーミング再生ができない(一回端末にダウンロードしてからじゃないと再生できない)のでせっかく良い画質で撮っても気軽に見えないという問題が発生。クラウドファイル管理だと動画の再生ができないことも多いので困っていましたが、会社で入れてみたNASがホームユースでも便利そうだったので、Windows PCベース、NASベース織り交ぜて、オンプレ環境がどういうのが良いか再考してみました。
○再生環境
今時動画を再生するのにいちいちPCを立ち上げることも少ないですよね、ということで今回はスマホアプリに特化した内容を記載します。おすすめアプリは BUZZ Player です。SMB、DLNAのどちらでも繋げることができて、一番スムースでした。
◯Windows PCベース
Windowsの機能としてメディア共有機能もあるのですが、ファイル形式による制約がありそうなので
割愛します。※間違っていたらごめんなさい m(_ _)m
・SMB(ファイル共有)かDLNAか?
いろいろアプリで比較してみたのですが、SMBよりDLNAのほうがよりストリームに最適化されているせいか full hd 60Pで切れる確率が低かったです。
・DLNAで飛ばす
Twonkey server(有料)
http://twonky.com/
Universal media server(無料)
http://www.universalmediaserver.com/
機能的にはDLNAベースということで同じです。細かい作りこみに関しては商用のTwonkey serverのほうができています。ただし、単にメディアファイルをストリーミングする、ということに絞って考えればどちらも同じ機能を果たせるかと思います。
という感じでしたのでUniversal media serverをIntel NUCで動かしていたのですが、現在は下記NASベースに構成を変えています。
◯NASベース
Synology DS215j
https://www.synology.com/ja-jp/products/DS215j
・基本機能
会社でNASを調べていた際に、イマドキのNASの機能の豊富に驚いたので家用に買ってしまいました。このNASで何ができるかというと、写真、動画、音楽、その他ファイルをどこからでも(家の中でも外からでも)、専用アプリ経由でストリーミング再生できます。家の中ではDLNA対応クライアントでFull HD 60pを再生できるし、外でも4GならHD動画も見れます。写真もかなりサクサク見えるし音楽も端末に入れなくて済みます。端末間でのファイル同期機能(dropboxのようなもの)もあり、それを数TBのHDDでちゃんとRAID組んで、5万以下。雑多なクラウドサービスを無理矢理繋げてお金かけるよりかずっと使い勝手良いです。ちなみにRDBMS(MariaDB), httpサーバ, Wordpress, magento, OpenERP, SugerCRM, git,tomcatなどワンクリックでインストール可能。何でもありかっ(´Д` )。
・ビデオ
DLNAでもファイル共有(SMB)でも飛ばせますし、独自アプリでストリーミングが可能です。Full HD 60Pの時はDLNA>File station>Video stationの順で切れることが少ないです(理由は不明)。CPUの能力が低い(ARMのデュアルコア800MHz)のでPCサーバーより辛いかと思ったのですが、今のところ同程度のパフォーマンスを出しています。
ということで最近はNASで全て完結させてます。クラウドもいいけどオンプレは安心しますね~
○再生環境
今時動画を再生するのにいちいちPCを立ち上げることも少ないですよね、ということで今回はスマホアプリに特化した内容を記載します。おすすめアプリは BUZZ Player です。SMB、DLNAのどちらでも繋げることができて、一番スムースでした。
◯Windows PCベース
Windowsの機能としてメディア共有機能もあるのですが、ファイル形式による制約がありそうなので
割愛します。※間違っていたらごめんなさい m(_ _)m
・SMB(ファイル共有)かDLNAか?
いろいろアプリで比較してみたのですが、SMBよりDLNAのほうがよりストリームに最適化されているせいか full hd 60Pで切れる確率が低かったです。
・DLNAで飛ばす
Twonkey server(有料)
http://twonky.com/
Universal media server(無料)
http://www.universalmediaserver.com/
機能的にはDLNAベースということで同じです。細かい作りこみに関しては商用のTwonkey serverのほうができています。ただし、単にメディアファイルをストリーミングする、ということに絞って考えればどちらも同じ機能を果たせるかと思います。
という感じでしたのでUniversal media serverをIntel NUCで動かしていたのですが、現在は下記NASベースに構成を変えています。
◯NASベース
Synology DS215j
https://www.synology.com/ja-jp/products/DS215j
・基本機能
会社でNASを調べていた際に、イマドキのNASの機能の豊富に驚いたので家用に買ってしまいました。このNASで何ができるかというと、写真、動画、音楽、その他ファイルをどこからでも(家の中でも外からでも)、専用アプリ経由でストリーミング再生できます。家の中ではDLNA対応クライアントでFull HD 60pを再生できるし、外でも4GならHD動画も見れます。写真もかなりサクサク見えるし音楽も端末に入れなくて済みます。端末間でのファイル同期機能(dropboxのようなもの)もあり、それを数TBのHDDでちゃんとRAID組んで、5万以下。雑多なクラウドサービスを無理矢理繋げてお金かけるよりかずっと使い勝手良いです。ちなみにRDBMS(MariaDB), httpサーバ, Wordpress, magento, OpenERP, SugerCRM, git,tomcatなどワンクリックでインストール可能。何でもありかっ(´Д` )。
・ビデオ
DLNAでもファイル共有(SMB)でも飛ばせますし、独自アプリでストリーミングが可能です。Full HD 60Pの時はDLNA>File station>Video stationの順で切れることが少ないです(理由は不明)。CPUの能力が低い(ARMのデュアルコア800MHz)のでPCサーバーより辛いかと思ったのですが、今のところ同程度のパフォーマンスを出しています。
ということで最近はNASで全て完結させてます。クラウドもいいけどオンプレは安心しますね~
Rでミリ秒を扱う [BI]
備忘録です
#秒の定義をmsec(ミリ秒)にする
options(digits.secs=3)
#msecまで含まれた文字列投入
t1 <- "2015/05/04 21:18:03.024"
#POSIXltに変換
d1 <- strptime(t1,"%Y/%m/%d %H:%M:%OS")
#値を確認
unclass(d1)
#秒の定義をmsec(ミリ秒)にする
options(digits.secs=3)
#msecまで含まれた文字列投入
t1 <- "2015/05/04 21:18:03.024"
#POSIXltに変換
d1 <- strptime(t1,"%Y/%m/%d %H:%M:%OS")
#値を確認
unclass(d1)
kintoneの帳票ソリューションを雑に試してみる
「kintoneは可視化が弱い」というのは何回かセミナーでちくちく申し上げていることですが、今回帳票出力を重視したい業務があったため帳票ソリューションを調べてみることにしました。
○5つもある、、
なんと2015/01月時点で5つもあります。
https://kintone.cybozu.com/jp/app/feature/feature02
しかも機能の説明が無くどれがいいか判断できない(--;)。比較サイトも無い。まあ特定のベンダーさんに肩入れできないという事情はあるのかもしれませんが、、、。ということでとりあえず一部試用できたのでユーザー視点で雑に比較してみました。
○おおまかな分類
(1)既存のBIツール(レポートツール)のレポート機能にkintoneからのデータ連携コネクタとkintoneアプリへの帳票出力ボタン追加するJavaScriptをセットにした系(長いw)
・OPROARTS Live for kintone
・ReportsConnect for kintone
・AIVYレポートデザイナー for SVF on kintone
これらはざっくり言うと「BIツールでできることは全部できる」のですが、「BIツールの難しさをそのままkintoneの世界に持ち込んでしまっている」とも言えます。なので業務部門の人が手放しに使えるかでいうと、×だと思います。
ツールは元々高機能であるので、操作の好みの視点と周辺の環境がクラウドかオンプレ(ローカル)かで決めることになると思います。個人的にはiReportはJasperで使ったことがありオープンソースで、いろいろなデータソースを選べるのでこの3つで選ぶならReportsConnect for kintoneかなと思いますが、オールクラウドを優先するならOPROARTSかなと。もうこれは編集画面を見て使いやすそうなものを選んで決めてください。周辺環境の構成は以下になります
アプリ名/出力サーバー/帳票作成クライアント
OPROARTS /クラウド/クラウド
ReportConector /クラウド/オンプレ(ローカル)
AIVYレポートデザイナー/オンプレ(ローカル)/オンプレ(ローカル)
ちなみにkintoneのデータを外部に飛ばさなくてはいけない出力サーバーがクラウドの場合に、kintone側でアクセス制限や証明書を設定している時は有償サポートが必要になったりすることがあるようです。
(2)差し込み印刷系
・プリントクリエイター
これは機能的に若干びっくりしました。なんと既存のPDFの文字とか枠とかを固定で読み込み、kintoneデータをそこに差し込みます。テーブルにも対応しているのですが、「え、想定以上の件数があったらどうなるの?」「はい、はみ出ます」w、、、。ということで動的に件数が変わる用途には向きません。ただ設定作業難易度はは他のツールよりも圧倒的にしきいが低く、30分もあればテスト帳票が作れるようになりますので業務部門でも使えそう。ちなみにあまり機能が無い割には「他アプリのレコードと紐付けてくれる」というkintone本体で実現して欲しくてしょうがない機能を実現してくれたりしています。今後の機能アップにも期待できそうです。
(3)中身の処理は不明だけれども人力で開発してくれる系
・Repotone
基本的に帳票の作成は都度作ってもらう前提らしいです。単票xx万の世界とのこと。逆にお金はあるけど作る時間は無い!という時に業務に踏み込んで作ってくれるという意味では楽かもしれません。
(4)その他のソリューション(5つ以外のもの)
・kintone Excel連携
これkintone導入でExcelを捨てようという中で邪道だと思っていたんですが、やっぱりユーザーは「Excelと同等に使える」ことを求めてくるため、ある程度はしょうがないかなという気が最近ではしています。徐々に試してみようかと思っています。
・Kintone connector for Qlikview
一応そういう使い方もできるなということで並べておきます。実際にはQVはレポート作成を得意とするBIではないのですが、環境が揃っているという意味ではこれはこれで魅力的かと。
○まとめ
長所短所あるので、難易度や構成や要件で決めることになります。とりあえず今回の要件はプリントクリエイターでしのいでみる予定です。
○5つもある、、
なんと2015/01月時点で5つもあります。
https://kintone.cybozu.com/jp/app/feature/feature02
しかも機能の説明が無くどれがいいか判断できない(--;)。比較サイトも無い。まあ特定のベンダーさんに肩入れできないという事情はあるのかもしれませんが、、、。ということでとりあえず一部試用できたのでユーザー視点で雑に比較してみました。
○おおまかな分類
(1)既存のBIツール(レポートツール)のレポート機能にkintoneからのデータ連携コネクタとkintoneアプリへの帳票出力ボタン追加するJavaScriptをセットにした系(長いw)
・OPROARTS Live for kintone
・ReportsConnect for kintone
・AIVYレポートデザイナー for SVF on kintone
これらはざっくり言うと「BIツールでできることは全部できる」のですが、「BIツールの難しさをそのままkintoneの世界に持ち込んでしまっている」とも言えます。なので業務部門の人が手放しに使えるかでいうと、×だと思います。
ツールは元々高機能であるので、操作の好みの視点と周辺の環境がクラウドかオンプレ(ローカル)かで決めることになると思います。個人的にはiReportはJasperで使ったことがありオープンソースで、いろいろなデータソースを選べるのでこの3つで選ぶならReportsConnect for kintoneかなと思いますが、オールクラウドを優先するならOPROARTSかなと。もうこれは編集画面を見て使いやすそうなものを選んで決めてください。周辺環境の構成は以下になります
アプリ名/出力サーバー/帳票作成クライアント
OPROARTS /クラウド/クラウド
ReportConector /クラウド/オンプレ(ローカル)
AIVYレポートデザイナー/オンプレ(ローカル)/オンプレ(ローカル)
ちなみにkintoneのデータを外部に飛ばさなくてはいけない出力サーバーがクラウドの場合に、kintone側でアクセス制限や証明書を設定している時は有償サポートが必要になったりすることがあるようです。
(2)差し込み印刷系
・プリントクリエイター
これは機能的に若干びっくりしました。なんと既存のPDFの文字とか枠とかを固定で読み込み、kintoneデータをそこに差し込みます。テーブルにも対応しているのですが、「え、想定以上の件数があったらどうなるの?」「はい、はみ出ます」w、、、。ということで動的に件数が変わる用途には向きません。ただ設定作業難易度はは他のツールよりも圧倒的にしきいが低く、30分もあればテスト帳票が作れるようになりますので業務部門でも使えそう。ちなみにあまり機能が無い割には「他アプリのレコードと紐付けてくれる」というkintone本体で実現して欲しくてしょうがない機能を実現してくれたりしています。今後の機能アップにも期待できそうです。
(3)中身の処理は不明だけれども人力で開発してくれる系
・Repotone
基本的に帳票の作成は都度作ってもらう前提らしいです。単票xx万の世界とのこと。逆にお金はあるけど作る時間は無い!という時に業務に踏み込んで作ってくれるという意味では楽かもしれません。
(4)その他のソリューション(5つ以外のもの)
・kintone Excel連携
これkintone導入でExcelを捨てようという中で邪道だと思っていたんですが、やっぱりユーザーは「Excelと同等に使える」ことを求めてくるため、ある程度はしょうがないかなという気が最近ではしています。徐々に試してみようかと思っています。
・Kintone connector for Qlikview
一応そういう使い方もできるなということで並べておきます。実際にはQVはレポート作成を得意とするBIではないのですが、環境が揃っているという意味ではこれはこれで魅力的かと。
○まとめ
長所短所あるので、難易度や構成や要件で決めることになります。とりあえず今回の要件はプリントクリエイターでしのいでみる予定です。
Talend Open Studio (ETLツール) でデータ統合(13)~kintoneにファイルを添付する [BI]
ファイル取得(GET)までやったので、ついでにファイル添付(PUT)のやり方も載せておきます。どちらかというと動かせるだろうということを確認したぐらいなので、実用するにはもう少しいじる必要がある設定になっていますが、誰かの参考になるかもしれないので載せておきます。
○ファイルをアップロードし、ファイルキーを取得
ジョブの左側のほうです。ファイルは"c:\tmp\test.zip"です。tLogRowでつないでいますが、サーバの応答を見ているだけで、実際に欲しいデータのfileKeyはこんな感じに設定すると、"c:\tmp\logs_file.log"に取得されます。
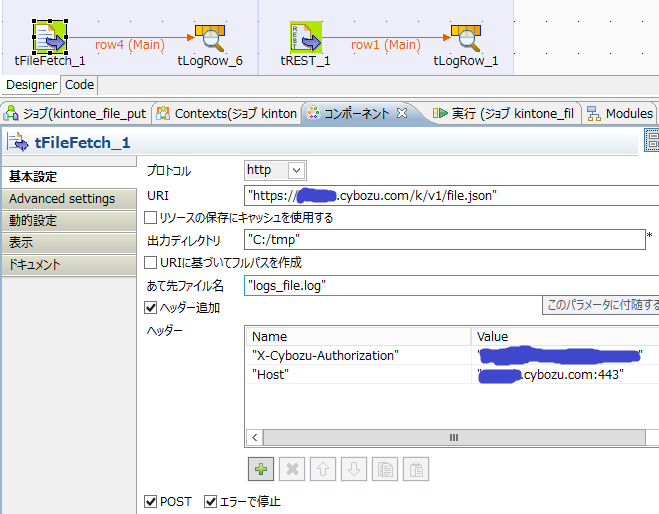
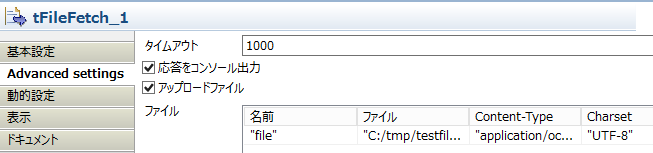
○アップロードしたファイルをAppに紐づける
この時点ではまだテンポラリ領域にファイルがアップされただけです。なので、紐づけるJSONをRESTで送ります。
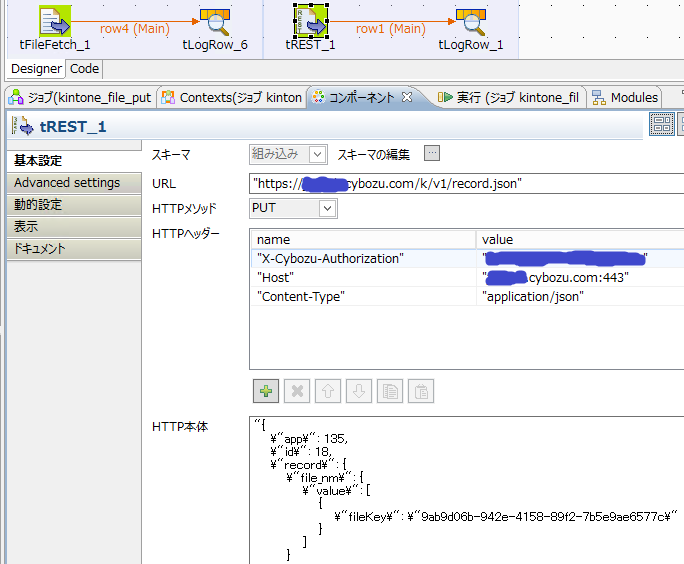
とりあえずこれでZIPファイルを転送して、kintoneの画面からダウンロードしたものが壊れず開けることまでは確認しました。ただ、今回は特に連続処理とかする予定がなかったのでBODYにそのままfileKeyを埋め込んでいます。実際にちゃんとしたjobを組む場合はfileKeyとapp-id,record-idの一覧から毎回JSONに変換するというコードを記述する必要があります。これは実際にやる必要ができたら試してみようと思います。
○ファイルをアップロードし、ファイルキーを取得
ジョブの左側のほうです。ファイルは"c:\tmp\test.zip"です。tLogRowでつないでいますが、サーバの応答を見ているだけで、実際に欲しいデータのfileKeyはこんな感じに設定すると、"c:\tmp\logs_file.log"に取得されます。
○アップロードしたファイルをAppに紐づける
この時点ではまだテンポラリ領域にファイルがアップされただけです。なので、紐づけるJSONをRESTで送ります。
とりあえずこれでZIPファイルを転送して、kintoneの画面からダウンロードしたものが壊れず開けることまでは確認しました。ただ、今回は特に連続処理とかする予定がなかったのでBODYにそのままfileKeyを埋め込んでいます。実際にちゃんとしたjobを組む場合はfileKeyとapp-id,record-idの一覧から毎回JSONに変換するというコードを記述する必要があります。これは実際にやる必要ができたら試してみようと思います。
Talend Open Studio (ETLツール) でデータ統合(12)~kintoneの添付ファイルをごっそり抜く [BI]
社内でとあるアイデアコンテストを開催し、投稿先をkintoneにしていたのですが、思いのほか件数が集まってしまったのでちまちまやるのは面倒くさいな~ということで一念発起でジョブを作りました。
○処理内容: 以下の(1)、(3)を
(1)とあるアプリのid,fileKey,ファイル名を取得し、テキストファイルで保存
(2)ファイル名に重複がある場合はリネームする(これは手動)
(3)上記のテキストファイルを元にファイルを連続ダウンロードする
○参考URL
https://developers.cybozu.com/ja/kintone-api/apprec-readapi.html
(1)とあるアプリのid,fileKey,ファイル名を取得し、テキストファイルで保存
全体はこんな感じです
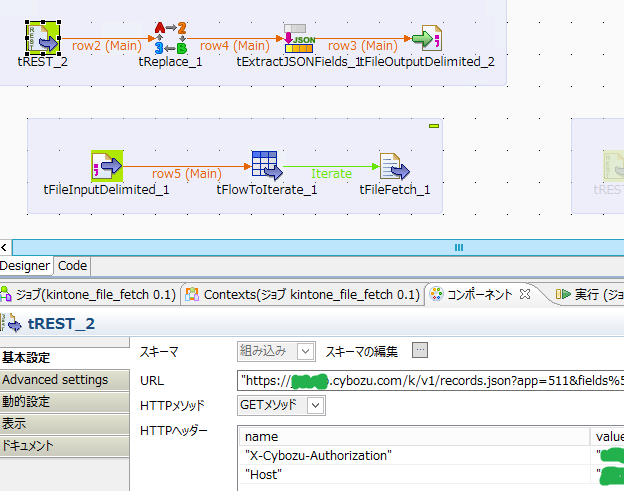
○RESTコンポーネント(tREST)
・URL
ここにアプリID、クエリをエンコードして記述します。例ではid=511のアプリに対して2つのフィールド("レコード番号($id)"と"filename")をOffset100をかけて持ってくるクエリを記述しています。
"https://(要変更).cybozu.com/k/v1/records.json?app=511&fields%5b0%5d=filename&fields%5b1%5d=$id&query=offset%20100"
※注意点1:&field[0]=ファイルのような形でエンコードしますが、
・"="や"&"はエンコードしない
・日本語のフィールドコードはUTF8でエンコードする
※注意点2:$idはtalendのJSONパーサーでエラーになりますので後段にtReplaceを配置。
・HTTPメソッド
GETを指定
・HTTPヘッダー
ログイン方法に応じてAuthorizationを指定、base64でユーザー名:パスワード をエンコードします。Hostも必須。
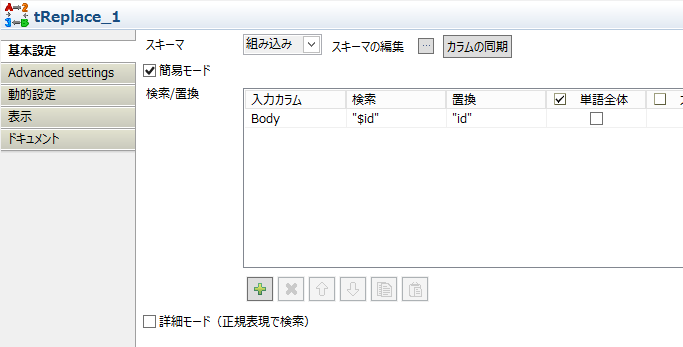
○tReplace
talendのJSONパーサーが"$"を扱えないので変換をかけます。ここではレコード番号の$idをidに変更しました。
○JSON変換(tExtractJSONFields)
・kintoneのJSONはトップにrecords(複数レコード抽出の場合)、その下にフィールドの構造がありますので、"フィールド名/value"のように指定します。
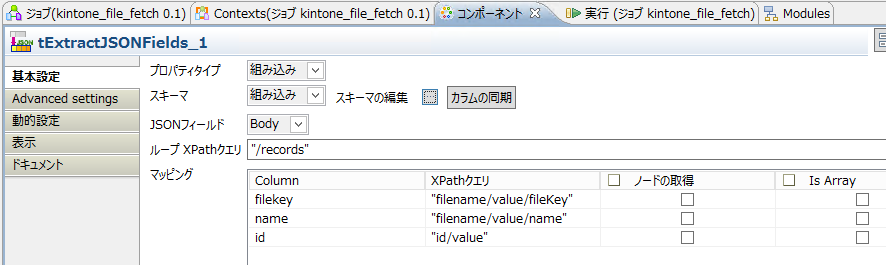
○テキスト保存
UTF8で3カラム分保存します。
これを実行すると、fileKey、ファイル名、IDが出力されます。100件以上ある場合はtRESTのクエリでoffsetをかけながらループをしてテキストファイルに追記モードで追加してください。
(2)ファイル名に重複がある場合はリネームする(これは手動)
上手く動いた!と思ったらファイル名重複でファイル数不足、、、的なことがあったのでご注意ください。
面倒なので今回は手でリストをリネームしました。
(3)上記のテキストファイルを元にファイルを連続ダウンロードする
テキストファイルをUTF8でInputから流します
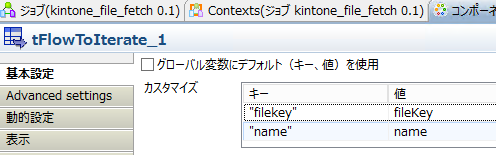
○tFlowToIterate
テキストファイルのデータをグローバル変数に入れて繰り返しを発生させます。後段とはIterateで繋いでください。
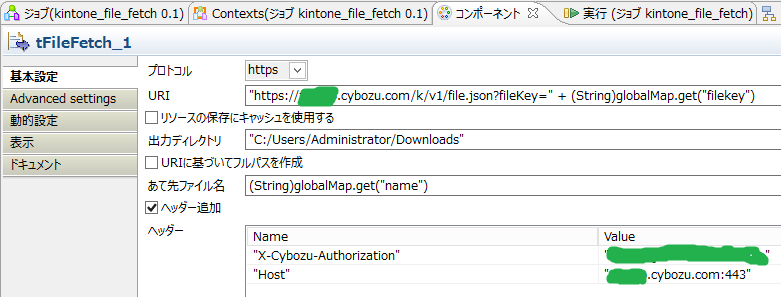
○tFileFetch
画像のような感じで設定すると、ファイル単位で連続処理が行われます。
○処理内容: 以下の(1)、(3)を
(1)とあるアプリのid,fileKey,ファイル名を取得し、テキストファイルで保存
(2)ファイル名に重複がある場合はリネームする(これは手動)
(3)上記のテキストファイルを元にファイルを連続ダウンロードする
○参考URL
https://developers.cybozu.com/ja/kintone-api/apprec-readapi.html
(1)とあるアプリのid,fileKey,ファイル名を取得し、テキストファイルで保存
全体はこんな感じです
○RESTコンポーネント(tREST)
・URL
ここにアプリID、クエリをエンコードして記述します。例ではid=511のアプリに対して2つのフィールド("レコード番号($id)"と"filename")をOffset100をかけて持ってくるクエリを記述しています。
"https://(要変更).cybozu.com/k/v1/records.json?app=511&fields%5b0%5d=filename&fields%5b1%5d=$id&query=offset%20100"
※注意点1:&field[0]=ファイルのような形でエンコードしますが、
・"="や"&"はエンコードしない
・日本語のフィールドコードはUTF8でエンコードする
※注意点2:$idはtalendのJSONパーサーでエラーになりますので後段にtReplaceを配置。
・HTTPメソッド
GETを指定
・HTTPヘッダー
ログイン方法に応じてAuthorizationを指定、base64でユーザー名:パスワード をエンコードします。Hostも必須。
○tReplace
talendのJSONパーサーが"$"を扱えないので変換をかけます。ここではレコード番号の$idをidに変更しました。
○JSON変換(tExtractJSONFields)
・kintoneのJSONはトップにrecords(複数レコード抽出の場合)、その下にフィールドの構造がありますので、"フィールド名/value"のように指定します。
○テキスト保存
UTF8で3カラム分保存します。
これを実行すると、fileKey、ファイル名、IDが出力されます。100件以上ある場合はtRESTのクエリでoffsetをかけながらループをしてテキストファイルに追記モードで追加してください。
(2)ファイル名に重複がある場合はリネームする(これは手動)
上手く動いた!と思ったらファイル名重複でファイル数不足、、、的なことがあったのでご注意ください。
面倒なので今回は手でリストをリネームしました。
(3)上記のテキストファイルを元にファイルを連続ダウンロードする
テキストファイルをUTF8でInputから流します
○tFlowToIterate
テキストファイルのデータをグローバル変数に入れて繰り返しを発生させます。後段とはIterateで繋いでください。
○tFileFetch
画像のような感じで設定すると、ファイル単位で連続処理が行われます。
Hyper-V 3.0 の仮想HDD(VHD)のフォルダ分け [雑多]
トラブル共有(笑)
物理サーバーで複数の仮想マシンを動かす場合、仮想HDDがかさんでくるので別ドライブで管理したいということはよくあると思います。ということで仮装HDDをd:¥vhdみたいなフォルダにまとめて5マシン分くらいまとめて入れておいたのですが、ある時親物理マシンのセキュリティアップデートで再起動しようとした際に仮想マシンを保存しようとしたら、何かしらのセキュリティロックがかかって保存できませんでした(´Д` )。何とかフォルダコピーしたり、フォルダ権限を再設定したりして一命をとりとめましたが、
もともとHyper-V では仮想マシン毎に設定ファイルや仮想HDDをフォルダを分けて保存するという仕様からくる挙動っぽいので、仮想HDDのフォルダは仮想マシン毎に分けた方がよさそうです。
物理サーバーで複数の仮想マシンを動かす場合、仮想HDDがかさんでくるので別ドライブで管理したいということはよくあると思います。ということで仮装HDDをd:¥vhdみたいなフォルダにまとめて5マシン分くらいまとめて入れておいたのですが、ある時親物理マシンのセキュリティアップデートで再起動しようとした際に仮想マシンを保存しようとしたら、何かしらのセキュリティロックがかかって保存できませんでした(´Д` )。何とかフォルダコピーしたり、フォルダ権限を再設定したりして一命をとりとめましたが、
もともとHyper-V では仮想マシン毎に設定ファイルや仮想HDDをフォルダを分けて保存するという仕様からくる挙動っぽいので、仮想HDDのフォルダは仮想マシン毎に分けた方がよさそうです。
前の10件 | -
komlog2 さん

-
nice! 33
記事 283
テーマ パソコン・インターネット
プロフィール
ブログを紹介する


